
How Nvidia Is Building the Backbone of the AI Economy: The $500 Billion Server Strategy Explained

Nvidia, once a niche graphics processing unit (GPU) manufacturer catering primarily to the gaming industry, has emerged as the foundational pillar of the artificial intelligence (AI) revolution. Over the past decade, the company has transformed into the world’s most influential provider of AI infrastructure, shaping the computational backbone of modern machine learning, deep learning, and generative AI models. In 2024, Nvidia made headlines by projecting a $500 billion total addressable market (TAM) for its AI server strategy—a bold yet increasingly plausible assertion given the technological and economic momentum underpinning its core business.
The catalyst for this transformation has been the meteoric rise of generative AI. Language models like OpenAI's GPT-4, Google’s Gemini, and Meta’s LLaMA series are no longer confined to research labs. These foundation models have become central to enterprise digital transformation efforts, redefining how software is written, data is processed, and decisions are made. At the heart of these models lies an insatiable appetite for compute power—specifically, the kind of accelerated computing that Nvidia’s GPUs, software stack, and integrated systems are uniquely positioned to provide.
Unlike traditional servers that depend heavily on central processing units (CPUs), AI workloads demand highly parallel architectures to efficiently execute tensor operations and neural network computations. Nvidia’s GPU platforms—spearheaded by its H100 and B100 Tensor Core GPUs—have become the industry standard for training and inference at scale. Moreover, Nvidia’s Grace Hopper superchips, InfiniBand networking technology, and DGX server systems now serve as the foundation of many AI data centers operated by hyperscalers such as Microsoft Azure, Amazon Web Services (AWS), and Google Cloud Platform (GCP).
The $500 billion opportunity Nvidia has identified is not simply a reflection of hardware sales. It encompasses a comprehensive and vertically integrated strategy spanning custom silicon, high-performance server architecture, interconnects, AI software libraries, and even AI-as-a-Service offerings. Nvidia aims to capture value at every layer of the AI computing stack—from the silicon that powers the models to the cloud services that make them accessible at scale.
This vision is underpinned by several converging macrotrends: the growing demand for sovereign AI infrastructure, the shift toward private and enterprise AI deployments, the rise of edge computing, and the international race for AI supremacy. With each of these trends comes a renewed need for specialized compute infrastructure—much of which will be designed, built, or powered by Nvidia.
However, the path ahead is not without competition or risk. Rival chipmakers such as AMD and Intel, as well as hyperscalers developing custom silicon (e.g., Google’s TPU, AWS Trainium), are investing heavily in alternatives to Nvidia’s hardware. Meanwhile, geopolitical tensions and export restrictions on high-end chips pose strategic uncertainties for Nvidia’s access to global markets.
Nonetheless, Nvidia’s integrated approach—melding cutting-edge hardware with mature software ecosystems such as CUDA, cuDNN, and AI Enterprise—gives it a defensible moat in a rapidly growing and fiercely contested industry. Its dominance in AI acceleration is already reshaping the landscape of global data centers, enterprise software, and cloud infrastructure.
This blog post will explore Nvidia’s $500 billion AI server strategy in detail. It begins with an examination of the market forces driving this explosive growth, then delves into Nvidia’s end-to-end hardware and software stack, analyzes its evolving monetization models, and assesses the competitive risks and future roadmap. Through this lens, we will better understand how Nvidia is positioning itself not just as a chipmaker, but as the infrastructure provider of the AI era.
Market Forces Fueling the AI Server Explosion
The global technology ecosystem is undergoing a seismic transformation, driven by the unprecedented rise of artificial intelligence. At the heart of this transformation lies the surging demand for AI servers—high-performance computing systems purpose-built for the training, inference, and deployment of complex machine learning models. Nvidia, the dominant player in the AI acceleration market, has projected a staggering $500 billion opportunity in this space, fueled by a confluence of macroeconomic, technological, and industrial forces that are rapidly reshaping the computing landscape.
The Rise of Generative AI and Foundation Models
One of the most consequential forces accelerating demand for AI servers is the rapid proliferation of generative AI models. Tools like OpenAI's ChatGPT, Anthropic's Claude, Google's Gemini, and Meta's LLaMA models have transitioned from experimental research projects to production-ready platforms adopted by millions of users. These models rely on transformer architectures with hundreds of billions—sometimes even trillions—of parameters, necessitating massive parallelism and computational throughput.
Training such models is no longer the domain of a handful of tech giants. Enterprises across industries—from finance and healthcare to retail and manufacturing—are now seeking to fine-tune foundation models or build their own proprietary models to gain competitive advantages. This paradigm shift is leading to a surge in AI infrastructure spending, specifically targeted at high-throughput, GPU-accelerated data centers.
Moreover, inference—the act of running models after training—is no longer a lightweight operation. Serving LLMs at scale demands high-performance inference clusters capable of low-latency, high-throughput responses. Nvidia’s AI server architecture is designed to address both ends of this spectrum: massive training compute and scalable, distributed inference.
Hyperscalers Lead the Charge
Cloud computing providers, often referred to as hyperscalers, are among the largest contributors to the exponential growth of the AI server market. Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), and Oracle Cloud Infrastructure (OCI) are engaged in a race to offer the most competitive AI cloud platforms. Each is investing billions in AI-specific data centers equipped with Nvidia GPUs, networking fabric, and software stacks optimized for model training and deployment.
In particular, Nvidia’s HGX and DGX platforms—based on GPUs like the H100 and the newer B100—have become a staple across hyperscale data centers. These servers are not only used to train internal foundation models, such as OpenAI’s GPT series on Azure or Gemini on Google Cloud, but also to support customer workloads through AI cloud services.
The increasing trend of “AI-as-a-Service” offerings from these hyperscalers has led to a virtuous cycle. As demand for AI model training and inference rises among startups and enterprises, hyperscalers must procure more Nvidia-powered AI server clusters to meet the growing appetite for compute.
Enterprises Embrace AI-Native Workloads
Beyond hyperscalers, the enterprise sector is witnessing a paradigm shift toward AI-native application development. Traditional software development pipelines are now being augmented with AI features such as natural language interfaces, autonomous agents, recommendation engines, predictive analytics, and multimodal input processing.
To support this transformation, organizations are investing in private AI infrastructure to retain control over their models, data, and intellectual property. Nvidia's strategy addresses this need with turnkey AI server solutions—DGX systems, SuperPOD configurations, and modular building blocks like the Grace Hopper superchip—all of which can be deployed on-premise or in colocation environments.
AI-first startups, particularly those focused on vertical applications such as legal, healthcare, and logistics, also represent a high-growth segment of AI server demand. These organizations often require dedicated compute environments optimized for low latency and high reliability, making Nvidia’s ecosystem an attractive proposition.
Edge AI and Sovereign AI Infrastructures
Two additional vectors of growth contributing to the AI server market expansion are edge AI and sovereign AI infrastructure.
Edge AI refers to the deployment of machine learning models closer to data sources—in factory floors, retail stores, autonomous vehicles, and mobile devices—rather than centralized cloud data centers. This model reduces latency, bandwidth usage, and privacy risks. Nvidia’s Jetson series and compact AI servers are tailored to this growing niche, enabling real-time inference at the edge with manageable power footprints.
Sovereign AI, on the other hand, has emerged as a geopolitical imperative. Governments and public institutions are increasingly investing in national AI infrastructure to safeguard data sovereignty, economic competitiveness, and regulatory compliance. Countries such as France, Germany, the United Arab Emirates, and China are building their own AI supercomputing facilities, many of which are based on Nvidia’s platform.
In this context, Nvidia’s $500 billion TAM estimate encompasses not only traditional data center environments but also a global proliferation of AI-optimized computing deployments in non-traditional sectors.
CPU vs GPU: A Structural Shift in Computing Paradigms
A fundamental reason behind Nvidia's strategic dominance is the architecture of its hardware. Traditional servers—powered primarily by x86 CPUs—are increasingly ill-equipped to handle AI workloads that require massive matrix multiplications, tensor operations, and parallel processing.
Nvidia’s GPUs are designed from the ground up to accelerate these operations. The company’s CUDA ecosystem, combined with powerful hardware accelerators like Tensor Cores, enables an order-of-magnitude improvement in performance per watt and per dollar compared to CPU-based alternatives.
This structural shift has led to a realignment of data center design principles. Whereas general-purpose servers dominated previous generations of IT infrastructure, the new wave of AI servers is built around specialized acceleration, with GPUs as the cornerstone of computational performance.
This has also forced legacy server manufacturers, such as Dell, Lenovo, and Hewlett Packard Enterprise (HPE), to partner closely with Nvidia, integrating its GPU technology into their next-generation offerings to remain relevant in a rapidly evolving market.
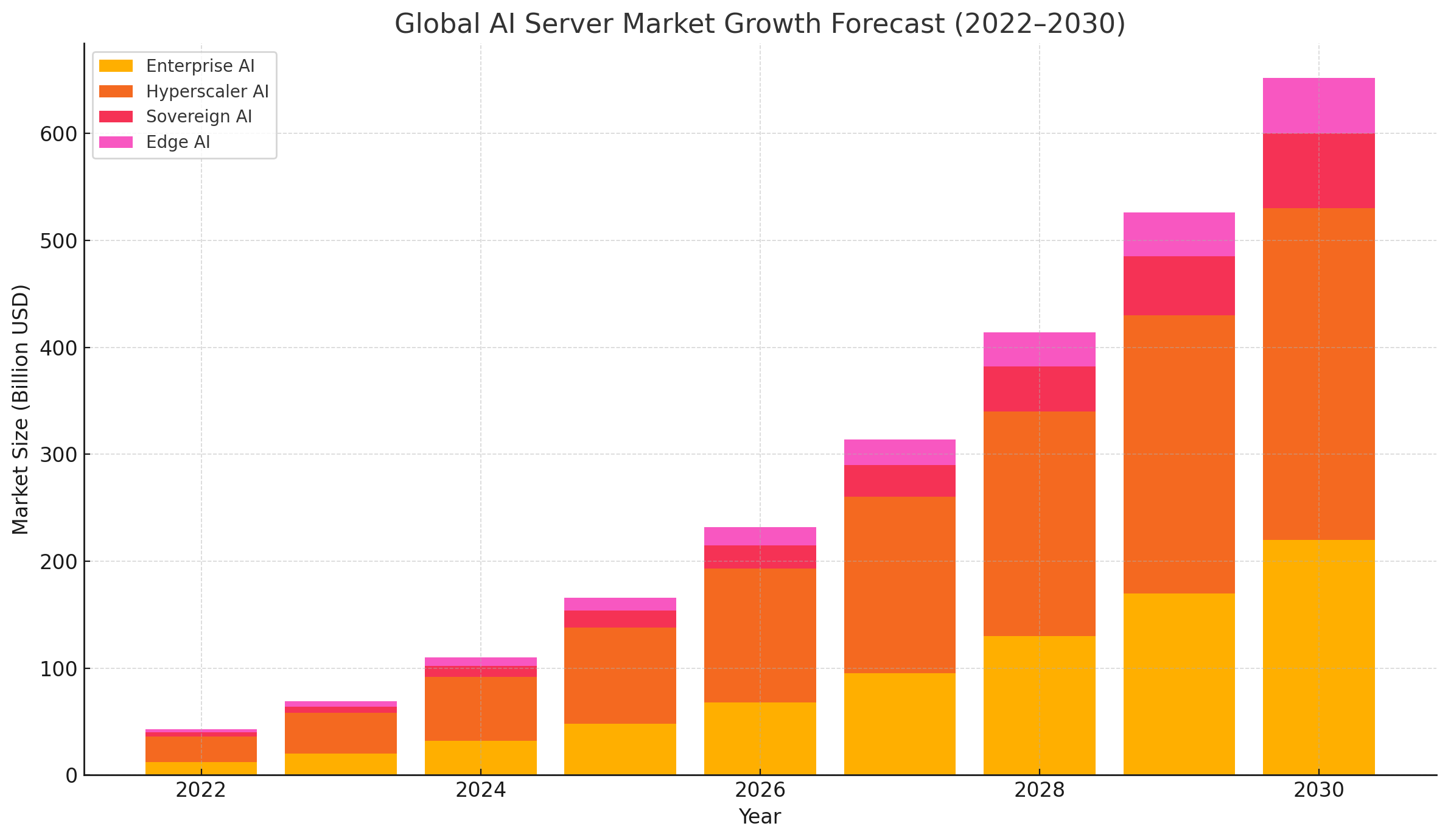
Nvidia’s End-to-End Server Stack – From Chips to Full Systems
Nvidia’s AI server strategy is not merely predicated on chip performance alone—it is rooted in an integrated approach that spans every level of the computing stack. From the silicon powering GPUs and custom CPUs to full-fledged server platforms, high-bandwidth networking interconnects, and a robust AI software ecosystem, Nvidia has positioned itself as a one-stop solution for scalable, enterprise-grade AI infrastructure. This vertical integration is central to the company’s vision for a $500 billion addressable market, and it is what enables Nvidia to dominate both performance benchmarks and market share in the AI compute sector.
The Core of the Stack: GPUs Purpose-Built for AI
At the core of Nvidia’s AI infrastructure lies its industry-leading lineup of graphics processing units (GPUs). While the GPU originally gained popularity in gaming and visualization, Nvidia’s reinvention of the GPU for parallel computing marked a pivotal inflection point for AI. Today, its Tensor Core architecture is the backbone of the world’s most advanced AI models.
The Nvidia H100, built on the Hopper architecture, was introduced as a successor to the A100 and quickly became the gold standard for training large language models and transformer networks. Featuring 80 billion transistors, advanced sparsity handling, and FP8 precision support, the H100 delivers substantial gains in training speed and energy efficiency.
Complementing it is the B100, the latest entrant in Nvidia’s GPU roadmap. Built for next-generation workloads, the B100 incorporates architectural innovations designed to support trillion-parameter models and next-generation inference engines with further enhanced memory bandwidth and interconnectivity.
Nvidia’s GPUs are equipped with Tensor Cores, specialized units designed to accelerate matrix multiplications—one of the most compute-intensive operations in neural network processing. Combined with support for reduced-precision formats like FP8 and INT4, Tensor Cores enable high throughput at lower power consumption, an increasingly vital requirement for hyperscale data centers.
Grace CPU and the Grace Hopper Superchip
While GPUs are the primary engines for AI workloads, traditional CPUs remain essential for system orchestration, preprocessing, and I/O management. Recognizing the inefficiencies of coupling its GPUs with off-the-shelf x86 CPUs, Nvidia introduced Grace—its first data center CPU based on Arm architecture.
Grace is optimized for memory bandwidth, latency-sensitive workloads, and deep integration with Nvidia’s software stack. By designing its own CPU, Nvidia can tightly align compute workloads across GPU and CPU domains, reducing bottlenecks and improving efficiency.
The Grace Hopper Superchip, launched as a unified module, combines the Grace CPU and the Hopper GPU into a single board connected via NVLink-C2C, a high-bandwidth interconnect that enables coherent memory sharing. This tight integration allows AI workloads to scale more efficiently across diverse data types and workload profiles, such as massive language models and real-time analytics.
The Grace Hopper system is particularly advantageous for AI workloads with large memory footprints. With support for up to 480GB of LPDDR5X CPU memory and up to 96GB of HBM3 GPU memory, it allows large models to be trained and executed with minimal latency and maximum memory efficiency.
Full System Integration: DGX and HGX Platforms
Nvidia's AI strategy extends beyond silicon into fully integrated server systems. The company’s DGX and HGX platforms are complete AI supercomputing solutions designed to deliver unparalleled performance, scalability, and reliability.
- Nvidia DGX Systems are turnkey solutions tailored for enterprises and research institutions that require ready-to-deploy AI infrastructure. A typical DGX system integrates 8 H100 GPUs interconnected via NVLink and powered by Grace CPUs, supported by liquid cooling, high-speed storage, and optimized software preloaded with Nvidia AI frameworks.
- HGX Platforms, in contrast, are modular and targeted at hyperscalers and system integrators. HGX systems offer flexible configurations—ranging from 4 to 8 GPUs—and allow for custom networking and storage solutions to meet specific workload requirements. HGX is used by OEMs like Dell, HPE, Lenovo, and Supermicro to build AI servers tailored to diverse deployment environments.
Both platforms benefit from NVLink and NVSwitch technology, which allows high-speed, low-latency communication between GPUs. This interconnect fabric is crucial for model parallelism and workload distribution across multiple accelerators.
In enterprise settings, DGX clusters—also known as DGX SuperPODs—are capable of training massive models in days instead of weeks, enabling organizations to move from prototype to production at unprecedented speed.

Networking: NVLink, NVSwitch, and InfiniBand
Nvidia's innovation does not stop at computation—it also encompasses networking and data movement. Traditional PCIe buses are insufficient for the volume and velocity of data transfer required in modern AI clusters. To address this, Nvidia developed:
- NVLink: A high-bandwidth, low-latency GPU interconnect enabling up to 900GB/s bidirectional bandwidth per connection.
- NVSwitch: A scalable switching fabric that allows all-to-all GPU communication within a server or across nodes.
- InfiniBand: Acquired through Mellanox, Nvidia’s InfiniBand products deliver high-speed, low-latency communication across large-scale clusters, making them essential for distributed training and multi-node inference tasks.
Together, these technologies eliminate interconnect bottlenecks, ensuring that compute capacity scales linearly with the number of GPUs.
Software: CUDA, cuDNN, and Nvidia AI Enterprise
What truly differentiates Nvidia from its competitors is its commitment to building a mature, developer-friendly software ecosystem. The CUDA platform, first introduced in 2006, provides a programming model and runtime that allows developers to harness GPU acceleration without needing to rewrite applications from scratch.
Complementing CUDA is cuDNN, Nvidia’s GPU-accelerated library for deep neural networks. CuDNN optimizes low-level operations such as convolutions, pooling, normalization, and activation—enabling higher throughput for AI frameworks such as TensorFlow, PyTorch, and JAX.
Nvidia AI Enterprise is a suite of software tools, pretrained models, APIs, and workflow automation libraries designed for businesses. It simplifies the deployment of AI across virtualized, hybrid, and cloud-native environments, including VMware, Red Hat OpenShift, and Kubernetes.
In this layered software architecture, developers can build, train, and deploy models without worrying about the underlying hardware, making AI more accessible to a broad range of organizations.
Summary
Nvidia’s dominance in the AI server market is not merely a consequence of fast GPUs. It is the result of a holistic, vertically integrated strategy that spans custom silicon, high-performance server systems, scalable networking, and a mature software ecosystem. From the transistor level to cloud-scale AI clusters, Nvidia delivers a tightly coupled, highly performant infrastructure stack that few, if any, competitors can replicate.
The AI workloads of tomorrow—from trillion-parameter models to real-time edge inference—require an architecture that balances power, performance, and scalability. Nvidia’s server platforms, built on its end-to-end hardware and software ecosystem, are engineered precisely for this future.
Monetization Strategy – From Hardware Sales to AI Services
Nvidia’s pursuit of a $500 billion AI server opportunity is underpinned not only by hardware innovation but also by a multifaceted monetization strategy that spans silicon, systems, software, and services. While the company’s dominance in GPU sales remains its financial bedrock, Nvidia has systematically evolved its business model to capture a greater share of value across the AI lifecycle—from development and deployment to orchestration and delivery. This strategic diversification transforms Nvidia from a component supplier into a platform company positioned at the center of the global AI economy.
The Hardware Revenue Engine: Chips and Systems
Nvidia's most recognizable source of revenue remains its chips—particularly GPUs such as the H100, A100, and B100. These components are critical for both AI training and inference workloads and represent the largest contributor to Nvidia’s data center revenue, which exceeded $20 billion in fiscal year 2024.
The margins on chips, especially in the data center segment, are substantial due to Nvidia’s strong pricing power, unmatched performance benchmarks, and high switching costs for customers. The company’s GPUs are widely regarded as essential for state-of-the-art AI model training, making them a near-mandatory purchase for hyperscalers, enterprises, and research institutions alike.
However, Nvidia’s evolution from a chip vendor to a systems provider has enabled it to capture additional revenue streams while offering greater value to its customers. Through its DGX and HGX platforms, Nvidia now sells fully integrated AI server systems that include multiple GPUs, CPUs, high-bandwidth memory, interconnects (NVLink/NVSwitch), and optimized cooling and storage solutions.
These systems command higher average selling prices (ASPs) and are typically sold to enterprises and government agencies that prefer turnkey solutions. As adoption of sovereign AI infrastructure and on-premise AI workloads expands, Nvidia’s systems revenue is expected to grow significantly. Furthermore, with the launch of products such as the DGX GH200, which combines 144 Hopper GPUs with Grace CPUs in a shared memory supercomputing platform, Nvidia has created a new category of high-value AI infrastructure.
Software Monetization: CUDA, AI Enterprise, and APIs
Historically, Nvidia offered most of its software free of charge, using it as a way to drive adoption of its hardware. However, the maturation of its developer ecosystem and the growing complexity of AI deployment have given Nvidia the opportunity to monetize software directly.
CUDA, Nvidia’s proprietary parallel computing platform, remains at the core of its ecosystem. While CUDA itself is not sold as a standalone product, it acts as a critical moat, locking developers into Nvidia’s GPU ecosystem and ensuring continued demand for its hardware.
More recently, Nvidia has introduced Nvidia AI Enterprise—a commercially licensed software suite that includes optimized frameworks, libraries, APIs, pretrained models, and orchestration tools. AI Enterprise supports environments such as VMware vSphere, Kubernetes, and Red Hat OpenShift, making it easier for enterprises to deploy and manage AI workloads across hybrid and multi-cloud environments.
This software suite is licensed on a per-GPU, per-year basis, enabling Nvidia to tap into recurring revenue streams. Customers value the enterprise-grade support, performance tuning, and security updates that come with a commercial license, particularly in regulated sectors such as finance, healthcare, and defense.
In addition to packaged software, Nvidia has begun to expose parts of its ecosystem as APIs and microservices. These include components of its NeMo framework (for building custom LLMs), Riva (for speech AI), and Clara (for medical imaging and genomics). By offering these capabilities on a usage-based model, Nvidia can scale its software revenue independently of its hardware shipments.
AI-as-a-Service: Nvidia's Next Frontier
Perhaps the most transformative development in Nvidia’s monetization strategy is the launch of AI-as-a-Service (AIaaS) offerings. This approach positions Nvidia not just as a provider of hardware or software, but as an end-to-end platform for AI model development, training, and deployment.
Nvidia AIaaS enables customers to access GPU-accelerated infrastructure, pretrained models, and full-stack AI tools via cloud platforms. These services are typically offered in partnership with hyperscalers such as Oracle Cloud Infrastructure (OCI), Microsoft Azure, and Google Cloud. Nvidia provides the software stack and reference architectures, while the cloud partners deliver the infrastructure and user interface.
Key offerings include:
- Nvidia AI Foundry Services: A managed service for model customization and deployment, combining base models (like those from NeMo) with fine-tuning tools and inference optimization.
- Inference Microservices (NIMs): Containerized AI inference services that allow rapid deployment of LLMs, vision models, and speech applications across cloud or on-premise environments.
- Omniverse Cloud: A platform for 3D content collaboration and simulation, offering services like synthetic data generation, digital twin development, and industrial robotics training—all powered by Nvidia GPUs and AI models.
The AIaaS model enables Nvidia to participate in the full AI value chain while establishing usage-based and subscription revenue streams. Importantly, it democratizes access to AI infrastructure for customers who may not have the capital or expertise to build their own clusters.
Strategic Partnerships and Ecosystem Expansion
Nvidia’s success in monetization is amplified by a vast and growing network of partners. System integrators, original equipment manufacturers (OEMs), independent software vendors (ISVs), and cloud service providers all form part of Nvidia’s extended go-to-market strategy.
Key ecosystem partnerships include:
- Dell, Supermicro, and Lenovo: OEMs that integrate Nvidia GPUs and networking into their own AI server offerings.
- VMware and Red Hat: Software partners that enable Nvidia AI Enterprise to run natively in enterprise data centers.
- Hugging Face and ServiceNow: Application partners leveraging Nvidia’s pretrained models and toolkits for natural language processing and generative AI applications.
- AWS, Azure, and GCP: Cloud partners that offer Nvidia-accelerated instances and managed AI services based on Nvidia reference architectures.
These partnerships reduce customer acquisition costs, accelerate adoption, and enable Nvidia to reach a broader audience beyond traditional HPC and research domains.
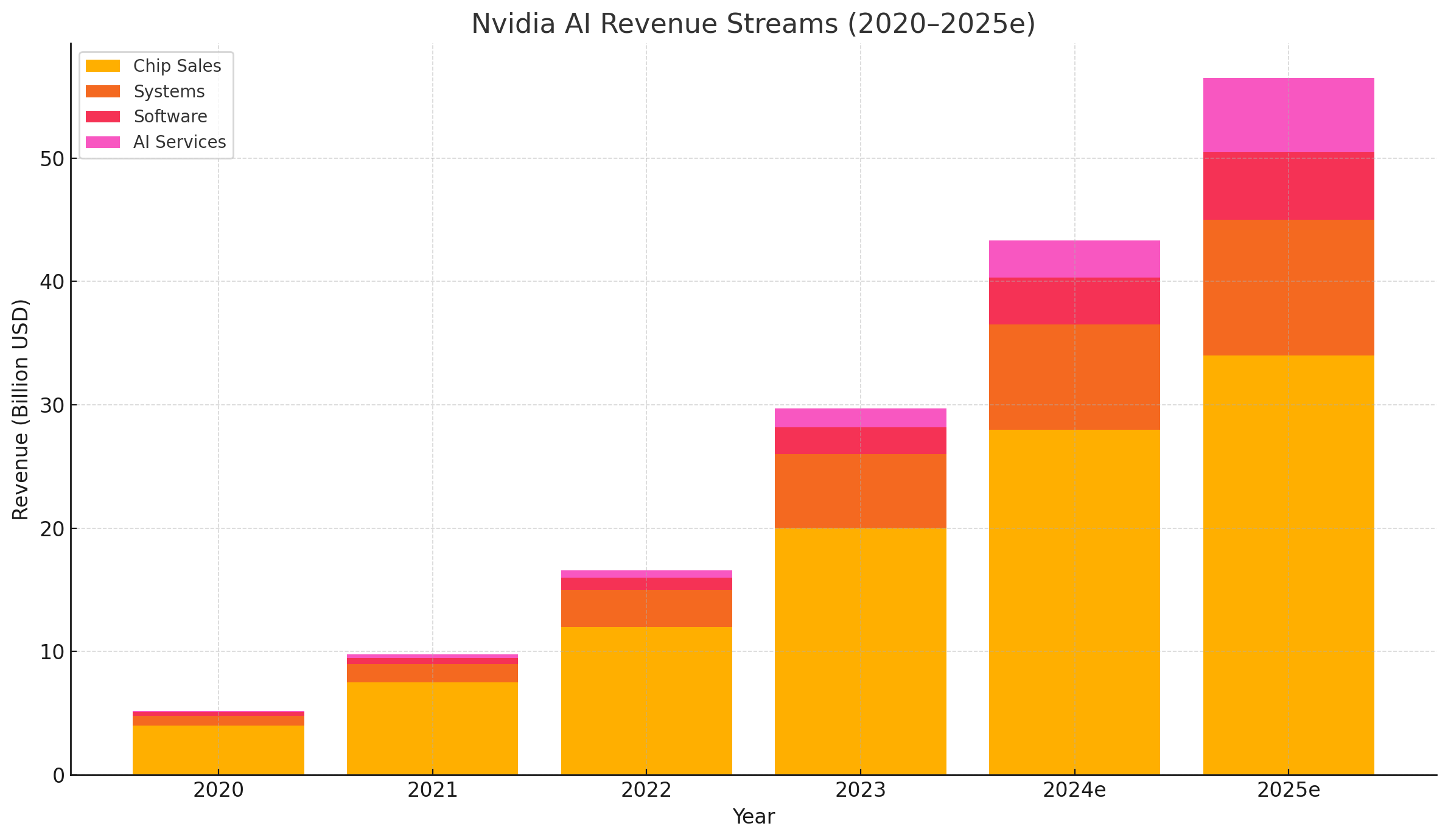
Summary
Nvidia’s monetization strategy exemplifies the shift from a product-centric to a platform-centric company. By expanding beyond chip sales into systems, software licensing, and cloud services, Nvidia has constructed a multi-layered business model capable of capturing value across the entire AI development lifecycle.
Each layer of this stack reinforces the others: software drives hardware adoption, systems increase share-of-wallet, and services create recurring, high-margin revenue. As AI becomes an infrastructural necessity across industries, Nvidia’s vertically integrated strategy positions it not just as a supplier, but as an indispensable AI platform partner for the digital economy.
Competitive Landscape, Strategic Risks, and Future Roadmap
As Nvidia continues to execute on its $500 billion AI server strategy, the landscape in which it operates is becoming increasingly dynamic. While the company has solidified its lead as the de facto provider of AI computing infrastructure, it faces formidable competition, growing geopolitical risks, and emerging challenges around power, scalability, and software differentiation. To sustain its dominance, Nvidia must not only defend its current advantages but also continuously innovate across the stack—both in silicon and software.
Competitive Pressures from Chipmakers and Hyperscalers
The most direct form of competition comes from other semiconductor companies aiming to erode Nvidia’s share in the AI compute market. Chief among these are Advanced Micro Devices (AMD) and Intel, both of which have made aggressive plays in the high-performance GPU and AI accelerator segments.
AMD’s MI300 series, based on the CDNA architecture, is designed to compete head-to-head with Nvidia’s H100 and Grace Hopper platforms. The MI300A and MI300X accelerators offer high memory bandwidth, increased AI-specific performance, and support for the ROCm software stack. AMD’s cost-performance advantage in certain inference workloads has made it a viable alternative, particularly for customers looking to diversify their infrastructure suppliers.
Intel, meanwhile, is pushing forward with the Gaudi 2 and Gaudi 3 AI accelerators through its Habana Labs division. While Intel has lagged behind in GPU development, its focus on AI-specific ASICs and integration with its expansive x86 ecosystem allows it to target enterprise buyers and hyperscalers with more vertically integrated stacks.
Beyond traditional chipmakers, Nvidia also faces competitive pressure from its own customers—namely, cloud hyperscalers. Companies like Google, Amazon, Microsoft, and Meta have begun developing custom silicon tailored for internal workloads. Examples include Google’s TPU v4, Amazon’s Trainium and Inferentia, and Microsoft’s newly announced Azure Maia and Cobalt chips.
These custom accelerators are optimized for the specific needs of their developers, and in some cases, outperform Nvidia GPUs for narrow workloads such as search ranking, recommendation engines, and inference-heavy applications. As hyperscalers grow their in-house silicon capabilities, they could reduce dependence on Nvidia—especially if their alternatives continue to scale in performance and software support.
Geopolitical Risks and Export Restrictions
A significant challenge to Nvidia’s global strategy comes from geopolitical tensions and evolving export control regimes. In particular, the U.S. government's restrictions on the sale of advanced AI chips to China, announced in multiple waves from 2022 onward, have affected Nvidia's ability to fully access one of its largest international markets.
Initially, Nvidia responded by introducing modified versions of its GPUs, such as the A800 and H800, which were designed to comply with U.S. export controls by limiting interconnect bandwidth and computational performance. However, as of late 2024, further tightened rules have restricted even these modified chips, complicating Nvidia’s ability to serve high-demand customers in China’s AI ecosystem.
This poses two interlinked risks. First, Nvidia risks losing a large and fast-growing segment of the global AI infrastructure market. Second, China has accelerated its investments in domestic alternatives, including efforts from Biren Technology, Huawei’s Ascend, and Alibaba’s T-Head, which seek to develop indigenous GPUs and AI accelerators. Over the long term, this could lead to bifurcation in the global AI chip market, with Nvidia dominant in the West and local alternatives rising in China and other geopolitically aligned regions.
Data Center Power and Sustainability Constraints
As Nvidia GPUs scale in performance, their power consumption has also risen significantly. The H100 GPU, for example, has a thermal design power (TDP) of approximately 700 watts, and the B100 is expected to push beyond 800 watts. When scaled across thousands of GPUs in hyperscale clusters, the total power demand becomes immense.
This has created a bottleneck in data center power availability and thermal management, especially in densely populated urban areas. In many jurisdictions, including the U.S. and EU, data center permits are increasingly tied to energy efficiency and carbon emissions targets. This creates operational friction for Nvidia’s largest customers and, indirectly, affects the pace of infrastructure deployments powered by Nvidia systems.
To address this, Nvidia is investing in more energy-efficient architectures and supporting liquid cooling technologies in its server designs. The Grace Hopper platform, for example, was engineered with power optimization in mind, thanks to Arm-based CPUs and improved memory coherency. Additionally, Nvidia collaborates with data center operators to optimize system layouts for cooling, density, and energy use.
However, sustainability remains a long-term concern that Nvidia must factor into its roadmap—not only for regulatory compliance but also to align with the environmental commitments of enterprise and government buyers.
The Rubin Roadmap and Future Innovation
Looking forward, Nvidia has outlined a detailed product roadmap designed to extend its leadership in AI compute. The next major architectural leap is expected to come from the Rubin platform, slated to succeed Blackwell in late 2026 or early 2027. Rubin is projected to bring significant advances in chiplet integration, optical interconnects, and photonics, enabling even greater scalability and efficiency.
In parallel, Nvidia continues to evolve its software and services strategy. Recent initiatives such as Nvidia Inference Microservices (NIMs), NeMo Guardrails, and Omniverse Cloud reflect a pivot toward platformization of AI workloads—providing modular, composable services that can be monetized independently of hardware.
Additionally, Nvidia’s increasing support for multi-node orchestration, model optimization, and automated fine-tuning pipelines signals a broader ambition to own not just the infrastructure layer, but the AI lifecycle end-to-end.
These innovations are not only aimed at staying ahead of competitors but also at mitigating customer churn toward alternative architectures. By embedding its software stack deeply into development workflows, Nvidia ensures long-term dependency, even in environments that may integrate third-party accelerators or edge compute devices.
Opportunities in Vertical Markets and AI Personalization
One of the underexplored avenues in Nvidia’s future strategy lies in vertical market customization and personalized AI services. With enterprise demand shifting from generic AI models to domain-specific, fine-tuned solutions, Nvidia has the opportunity to offer preconfigured, application-centric hardware/software bundles.
For instance, Nvidia’s Clara platform targets healthcare and life sciences, while its Isaac platform focuses on robotics and industrial automation. These sector-specific initiatives could drive growth in highly regulated or specialized industries that require not only compute but also compliance, pretraining, and workflow integration.
The rise of AI copilots, autonomous agents, and real-time decision engines will further increase the demand for low-latency inference capabilities at scale. Here, Nvidia’s leadership in both cloud and edge AI compute—via Jetson, Orin, and new AI PCs—could unlock new revenue streams in markets previously untouched by traditional data center GPUs.
Why Nvidia’s $500B AI Server Vision May Be Just the Beginning
Nvidia’s unprecedented rise from a graphics processor manufacturer to the bedrock of the global AI infrastructure ecosystem represents one of the most significant transformations in modern technology history. Its $500 billion AI server strategy is more than a financial projection—it is a calculated response to a series of converging trends that are reshaping enterprise IT, cloud computing, national infrastructure, and digital economies at large.
By anchoring itself at the center of AI workloads—training, inference, orchestration, and deployment—Nvidia has successfully redefined the computing stack. The company’s combination of performance-leading GPUs, purpose-built CPUs, integrated server systems, high-speed networking, and end-to-end software ecosystems has no direct peer. Its ability to monetize not only silicon but also complete systems, enterprise software, and AI-as-a-Service offerings provides it with a defensible moat and an expansive growth runway.
The growth of large language models, generative AI applications, and enterprise AI deployments continues to drive unprecedented demand for scalable, high-performance compute. Simultaneously, new growth vectors such as sovereign AI infrastructure, edge computing, and industry-specific AI workloads are opening fresh markets that align squarely with Nvidia’s offerings.
Yet, the path forward is not without challenges. Competitive forces from AMD, Intel, and hyperscaler in-house chips, combined with geopolitical risks and environmental concerns, present ongoing obstacles that Nvidia must carefully navigate. Moreover, the need for global compute infrastructure to become more sustainable, efficient, and democratically accessible adds complexity to Nvidia’s roadmap.
Still, Nvidia’s proactive approach to innovation—epitomized by its evolving hardware architectures (from Hopper and Blackwell to Rubin), its growing suite of AI microservices, and its platformization of model development—suggests that it is uniquely prepared to not only defend but expand its leadership in the AI era.
If the AI revolution is comparable to the dawn of the internet or the rise of mobile computing, then Nvidia’s role is analogous to that of a foundational utility—like Intel during the PC era or AWS during the cloud revolution. The $500 billion figure may represent the AI server market’s scale in the near term, but given the expanding role of AI in every aspect of industry and society, Nvidia’s influence and impact could well exceed even its most ambitious forecasts.
For enterprises, policymakers, and technologists alike, understanding Nvidia’s strategy is no longer optional—it is essential to navigating the future of digital transformation. Whether building sovereign AI, fine-tuning industry-specific models, or optimizing real-time analytics at the edge, Nvidia is increasingly the infrastructure partner of record.
In sum, the $500 billion AI server strategy is not the endpoint—it is a milestone. What comes next may very well define the next era of global computing.
References
- Nvidia’s H100 Tensor Core GPU Architecture
https://www.nvidia.com/en-us/data-center/h100/ - Nvidia Blackwell: Advancing AI Model Training
https://blogs.nvidia.com/blog/nvidia-blackwell-gpu-architecture/ - Nvidia Grace Hopper Superchip Overview
https://www.nvidia.com/en-us/data-center/grace-hopper-superchip/ - DGX GH200 AI Supercomputer
https://www.nvidia.com/en-us/data-center/dgx-gh200/ - Nvidia AI Enterprise Software Suite
https://www.nvidia.com/en-us/software/ai-enterprise/ - Nvidia NeMo Framework for LLMs
https://developer.nvidia.com/nemo - Nvidia AI Foundry Services Explained
https://blogs.nvidia.com/blog/nvidia-foundry-service-ai/ - AMD Instinct MI300 Series Accelerators
https://www.amd.com/en/products/instinct-mi300 - Intel Gaudi AI Accelerators Overview
https://www.intel.com/content/www/us/en/products/docs/processors/gaudi/overview.html - U.S. Government Semiconductor Export Restrictions
https://www.reuters.com/technology/us-expands-restrictions-ai-chip-exports-china/