
How Ant Group Cut AI Costs by 20% with Chinese Chips and MoE Models

Ant Group—the fintech powerhouse behind Alipay—has achieved a remarkable 20% reduction in AI computing costs by pairing domestic Chinese semiconductors with cutting-edge Mixture-of-Experts (MoE) machine learning models. This cost breakthrough is not just a one-off tweak but part of a broader strategy in China’s tech industry to curb skyrocketing AI expenses and reduce reliance on foreign hardware. In this article, we’ll explore Ant Group’s motivation and methods, dive into how MoE models work and why they’re efficient, examine the Chinese-made chips enabling this shift, and compare Ant’s approach with similar moves by Baidu and Alibaba Cloud. We’ll also contrast these domestic solutions with NVIDIA’s offerings in terms of cost, performance, and ecosystem and discuss what these developments mean for China’s AI and semiconductor landscape.
Motivation: Why Ant Group Needed to Reduce AI Costs
The motivation behind Ant Group’s cost-cutting strategy lies at the intersection of economics and geopolitics. On the one hand, the demand for AI capabilities (like large-scale language models, recommendation systems, fraud detection, etc.) has exploded, driving surging corporate AI investments. Training and deploying advanced AI models is enormously resource-intensive—requiring thousands of compute-hours on specialized hardware—which translates into very high costs. As a fintech company operating at massive scale, Ant Group must control these expenses to keep services affordable and competitive. Every percentage point saved in AI infrastructure cost can directly improve the bottom line or be passed on as better services to users. A 20% cost reduction is therefore a significant boost to efficiency, allowing Ant to do more with the same budget.
Equally important is technological self-reliance. U.S. export restrictions have made it harder and costlier for Chinese firms to obtain the latest high-end AI chips from Nvidia. For example, Nvidia’s advanced A100 and H100 GPUs (graphics processing units), which are the gold standard for AI training, are heavily regulated for export to China. Even Nvidia’s special China-only variants (A800, H800) are now restricted as of late 2023. This created urgency for Chinese companies to find alternatives. Ant Group’s push to use domestic chips from Alibaba and Huawei—rather than exclusively NVIDIA—is a direct response to these constraints. Relying on homegrown semiconductors mitigates the risk of supply cut-offs and reduces dependency on a single foreign supplier (NVIDIA). It also aligns with China’s national strategy of building a resilient local semiconductor ecosystem.
Another motivation is philosophical: Ant’s approach contrasts with Nvidia CEO Jensen Huang’s view that advancing AI is best achieved with ever more powerful (and expensive) GPUs. Huang has argued that companies should focus on bigger, faster chips to drive AI forward (and Nvidia’s revenue) rather than on cost-cutting measures. Ant Group is taking the opposite stance—seeking innovation in efficiency rather than brute-force performance. By doing so, Ant aims to “eliminate reliance on high-end GPUs” altogether in the long run. This strategic pivot is driven by the belief that smarter algorithms and diversified hardware can deliver required AI performance at lower cost. It’s a strategy of optimization over raw power—one that could democratize AI by making it cheaper to train and deploy models.
In summary, Ant Group’s cost-reduction push is motivated by a mix of economic necessity (taming AI infrastructure costs), supply chain security (localizing chip supply under export curbs), and a vision for sustainable AI (doing more with less). Next, we’ll see how the Mixture-of-Experts (MoE) technique is a key enabler of this vision.
Mixture-of-Experts (MoE)
How It Works and Why It’s Cost-Efficient
At the heart of Ant Group’s breakthrough is its use of Mixture-of-Experts (MoE) models. MoE is a machine learning approach that divides a large model into many smaller “expert” networks, each specializing in certain types of input or subtasks. Instead of activating the entire neural network for every input, an MoE model intelligently routes each input to only a subset of experts that are most relevant. In effect, the model mixes the outputs of a few selected experts (hence “mixture of experts”) to produce a result, rather than relying on one monolithic model.
This architecture allows models to scale up to huge numbers of parameters (many billions) while greatly reducing computation per query. Only the necessary experts are engaged for a given task, sparing the computation that would have been wasted running parts of the model that don’t contribute to that particular input. The efficiency gains are significant: large MoE models can be trained and run at a fraction of the cost of equally large dense models (traditional models where all parameters are active for each input). As IBM explains, MoE “enables large-scale models… to greatly reduce computation costs during pre-training and achieve faster performance during inference” by selective activation. Essentially, MoE offers a sweet spot between the greater capacity of big models and the efficiency of smaller models.
To illustrate, Ant Group’s research team recently trained a 290-billion-parameter MoE language model (Ling-Plus) where only about 28.8 billion parameters are activated per input. In comparison, a dense model with 290B parameters would activate all 290 billion for every input. By using MoE, Ant’s model achieves similar expressiveness and accuracy to a dense 300B model, but the effective compute per token is only ~10% of the full model size. The result: a large-scale AI model that can be trained on lower-performance, lower-cost devices without sacrificing output quality. In their experiments, the Ant Group team demonstrated that this 300B MoE model matched the performance of dense models of similar scale yet could be trained with approximately 20% lower computing costs by using “lower-specification hardware” instead of only premium GPUs. In other words, MoE unlocked the ability to train a giant model on cheaper or fewer chips, yielding a one-fifth cost savings for the same performance level.
It’s not just Ant Group. Mixture-of-Experts is gaining traction industry-wide as a path to efficiency. Google introduced MoE in its Switch Transformer and GShard models; researchers noted massive models with MoE can reach target accuracy in half the training epochs of a dense model in some cases (an early MoE paper found training was 2× faster to reach target accuracy). OpenAI’s GPT-4 is rumored to use MoE internally, and recent startups are built entirely around MoE-based architectures. China’s DeepSeek AI model is another notable example—it employs a new technical approach (reportedly involving expert-model distillation) to achieve GPT-4 level results with only 5–10% of the training cost of Western models. Alibaba has also embraced MoE for its flagship models: the latest Alibaba Qwen-2.5 Max model uses an MoE-based architecture that runs on 70% fewer FLOPs (floating-point operations) compared to a dense model of similar capability. This translates to major cost savings—Qwen’s MoE approach is one of the most cost-efficient at scale, delivering 30% faster responses while slashing compute needs.
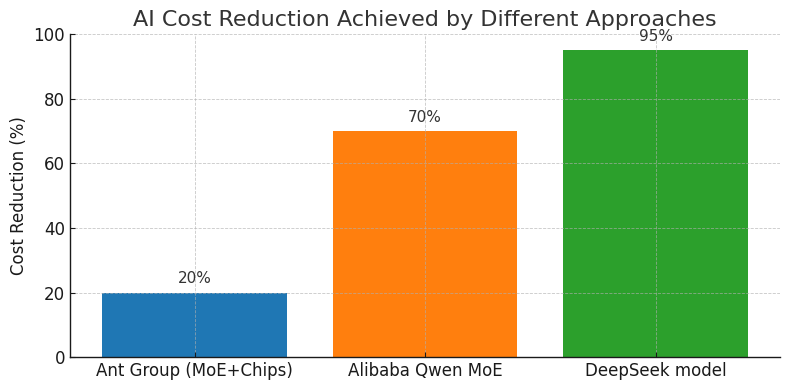
Figure 1: AI cost reduction achieved by different approaches. MoE-based strategies dramatically cut computing requirements versus traditional methods. Ant Group’s MoE+Chinese-chips approach yields ~20% cost savings. Alibaba’s MoE-based Qwen model uses ~70% less compute than an equivalent dense model. DeepSeek’s techniques (MoE and distillation) reportedly reduce costs by ~95% compared to OpenAI models.
For a non-technical reader, think of MoE like a team of specialists tackling a task instead of one giant generalist. If a question is about math, only the “math expert” part of the model wakes up to answer it, while the “history expert” and “language expert” parts stay idle. Ask a history question, and the history expert is engaged. This way, each query utilizes only a slice of the model’s total expertise, saving a lot of effort. Yet, because the model has many experts, the overall knowledge and skill (parameters) are vast. It’s an efficient use of resources—akin to consulting a panel of experts but only paying those who actually contribute an answer.
From a cost perspective, MoE means you don’t need as many high-end chips to train a large model. You can distribute different experts across different hardware and train them somewhat independently, aggregating the knowledge. The computational load per device is reduced, which is exactly what Ant Group exploited: they trained their huge Ling-Plus model on a mix of lower-cost hardware (including Chinese-made chips) and still got top-tier results. By contrast, training a 300B dense model might have required a large cluster of Nvidia H100 GPUs – an extremely expensive proposition (likely tens of millions of dollars in hardware and power). MoE provided Ant a clever shortcut to big-model results on a smaller budget.
It’s worth noting MoE models can be more complex to implement—e.g., a gating network is needed to route inputs to experts, and balancing the load between experts (to avoid some being overused or underused) is an active research area. But frameworks and libraries for MoE have matured, and success stories from Google, Microsoft (Turing MoE), Amazon, and now Ant/Alibaba/DeepSeek in China are accelerating adoption.
In summary, Mixture-of-Experts reduces cost by optimizing computation: why spend GPU cycles on parts of a model that aren’t needed for a given input? This fundamental idea allowed Ant Group to maintain model performance while trimming 20% of the training cost. With the MoE concept explained, let’s examine the other half of Ant’s equation: the domestic Chinese semiconductors that powered this cost-efficient AI training.
Chinese Semiconductors: Powering Ant’s AI on Homegrown Chips
A critical factor in Ant Group’s 20% cost reduction was its use of Chinese-made AI chips in lieu of (or alongside) the usual Nvidia GPUs. According to Bloomberg’s report, Ant leveraged semiconductors from Alibaba and Huawei for training its models. This is significant because it demonstrates that domestic chips have reached a level of performance where they can meaningfully contribute to large-scale AI workloads. Let’s explore these chips and what they’re capable of:
- Huawei Ascend AI Processors: Huawei’s Ascend 910 is a prominent domestic AI accelerator, first launched in 2019. Fabricated at 7nm, the Ascend 910 originally boasted up to 256–320 TFLOPS of FP16 performance (i.e., it can perform ~320 trillion half-precision operations per second). This put it in the same league as Nvidia’s A100 GPU – indeed 320 TFLOPS FP16 is roughly comparable to the A100’s peak. The Ascend 910 comes with on-chip high-bandwidth memory (32GB HBM) and was designed for both training and inference. Huawei has since released updated versions like Ascend 910B/910C, produced domestically by SMIC. Recent research by the Chinese AI firm DeepSeek found that the Ascend 910C delivers about 60% of Nvidia H100’s inference performance – an impressive feat given H100 is Nvidia’s latest flagship. While Ascend 910C is not a “performance champion” and still falls short for the most demanding training tasks, it succeeds in reducing reliance on Nvidia by being “good enough” for many purposes. Notably, DeepSeek was able to integrate Ascend chips into standard AI workflows by adapting software (they provide a toolkit to convert CUDA code to Huawei’s CANN toolkit with minimal effort). This shows that the ecosystem for Chinese AI chips is maturing: frameworks like Huawei’s MindSpore and compatibility layers mean models can be trained on Ascend with relative ease. Ascend’s strength has been heavily utilized in inference (running trained models) – e.g. data centers in China have deployed Ascend chips for AI services, and Huawei reports that with kernel optimizations, Ascend’s efficiency improves further. So, when Ant Group used Huawei’s chips, they likely tapped into Ascend 910’s considerable compute power for portions of the model training or for inference serving, at a lower cost than renting scarce Nvidia GPUs. The power draw of Ascend 910 (~310W) is similar to GPUs, but the availability and cost in China can be better since Huawei can supply them domestically.
- Alibaba’s In-House AI Chips: Alibaba, via its chip subsidiary Pingtouge (T-Head), has developed AI accelerators as well. The notable one is Hanguang 800, unveiled in 2019 as a cloud inference chip. Hanguang 800 is a 12nm chip with 17 billion transistors specialized for neural network inference. It’s incredibly fast for specific tasks – at Alibaba’s cloud conference, they reported Hanguang 800’s peak throughput at 78,563 images per second on ResNet-50 (a standard image recognition benchmark). This was about 15× faster than Nvidia’s T4 GPU (a popular inference GPU), making it one of the world’s most advanced neural network chips for inference at the time. Its efficiency was quoted as 500 IPS/W, and Alibaba used it internally to achieve 12× higher image processing efficiency than GPUs in some e-commerce workloads. While Hanguang 800 is more geared toward inference (vision, recommendation, etc.) and not typically used for training huge language models, it exemplifies Alibaba’s semiconductor capability. For Ant Group’s purposes, Alibaba’s contribution might also include hardware from Alibaba Cloud’s infrastructure – for instance, Alibaba Cloud has deployed custom chips and possibly alternative GPUs (like AMD MI series or even Chinese startup chips) in its data centers. The TechNode report specifically says Ant used chips from Alibaba, which suggests either Hanguang 800 or some Alibaba-co-developed solution. It’s worth noting Alibaba also invests in RISC-V CPUs (Xuantie series) and has an upcoming 5nm AI inference chip in the works. By incorporating Alibaba’s chip tech, Ant Group could perform parts of model training or large-scale inference on hardware that is locally optimized and possibly lower-cost (since Alibaba isn’t charging itself a premium).
- Baidu Kunlun AI Chip: Although not explicitly named in Ant’s case, Baidu’s Kunlun chips are another domestic semiconductor worth comparing. Baidu’s Kunlun II (second-gen) was introduced in 2021 on a 7nm process. It delivers about 128–192 TFLOPS of FP16 performance(2–3× faster than Kunlun I, which was 14nm). In practical terms, Kunlun II’s throughput is on the order of 40–60% of an Nvidia A100’s, meaning it can handle heavy AI computations albeit at somewhat lower speed. Baidu uses these chips in its own AI products and cloud – for example, they reported that deploying Ernie (their LLM) on Kunlun hardware gave strong inference performance with lower cost. Kunlun chips support training and inference and integrate with Baidu’s PaddlePaddle AI framework. Like others, Baidu still used many Nvidia GPUs for highest-end training, but Kunlun provides an in-house option that avoids Nvidia’s premium. The memory on Kunlun II (we can infer it uses high-bandwidth memory or similar) and ~120W TDP make it efficient. Baidu’s strategy has been to incorporate Kunlun wherever feasible to drive down cost and dependency. (We’ll revisit Baidu’s usage later.)
In using Chinese chips, Ant Group is harnessing these capabilities. While Nvidia GPUs still set the benchmark for absolute performance and software support, the gap is closing. Table 1 below compares some key specs and cost/performance aspects of these chip solutions:
Table 1: AI Hardware Comparison – Domestic Chinese Chips vs Nvidia and Others
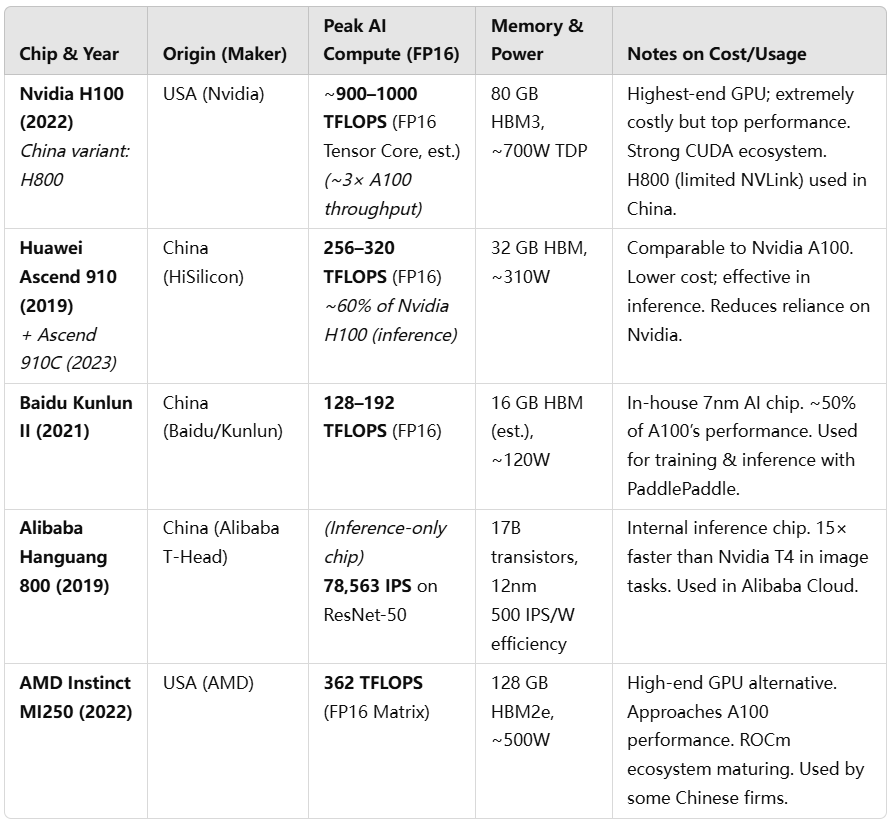
Table 1: Technical specs and cost-performance notes for selected AI hardware. Domestic Chinese chips like Huawei’s Ascend 910 and Baidu’s Kunlun II now reach roughly 40–60% of the performance of Nvidia’s latest (H100) in raw compute, and match previous-gen Nvidia chips in some cases. While Nvidia still leads in absolute capability and software, Chinese accelerators offer sufficient performance at lower cost, helping to reduce dependency. Alibaba’s Hanguang 800 targets inference efficiency, and AMD’s MI250 provides a non-Nvidia option for training.
Several points emerge from this comparison:
- Performance: Nvidia’s H100 is in a class of its own, but Chinese chips like Ascend 910 are competitive with the previous top GPU (A100). In fact, experts note Huawei’s achievement in producing a chip comparable to A100 despite sanctions. For many AI tasks (especially inference), an Ascend 910 or Kunlun II can do the job well enough. If training a model takes 20% longer on Kunlun II vs A100, that might be acceptable given cost savings. Ant Group reported that using these lower-spec devices in pre-training still achieved “comparable performance” in the end.
- Cost & Availability: Precise pricing for these chips isn’t public, but indications are that domestic chips come at lower cost or greater availability in China. For instance, Baidu’s purchase of 1,600 Huawei Ascend 910B chips in 2023 was about ¥450 million (≈$62M)– roughly $38,000 per chip if that cost is primarily the silicon. This is likely cheaper than black-market Nvidia A100s which during shortage times exceeded $50k each. Moreover, domestic chips are not subject to U.S. export bans, making them easier to procure in quantity. Nvidia’s restricted supply has, at times, created a frenzy in China, with companies scrambling for limited A800/H800 stock. By contrast, Huawei reportedly plans to produce 1.4 million units of Ascend 910C in 2025 to meet demand. This scale could drive down unit costs and ensure Chinese firms like Ant have ample hardware.
- Power Efficiency: A related cost factor is power consumption. Many Chinese accelerators are designed for efficiency in specific operations (e.g., Hanguang 800’s 500 images/sec/W is excellent for vision tasks). If a domestic chip uses less electricity for the same inference workload, that lowers operational cost. While Nvidia GPUs excel broadly, they might not be as optimized for certain tasks as custom NPUs like Hanguang, which shines at image recognition (Aliyun saw 12× efficiency gain vs GPU in a real application). Ant Group likely takes such factors into account for inferencing at scale – e.g., using Hanguang or other NPUs to serve AI models to hundreds of millions of users could be far cheaper than using power-hungry GPUs.
- Software Ecosystem: Historically, one challenge with non-Nvidia hardware was software compatibility. Nvidia’s CUDA and cuDNN libraries are deeply integrated into AI development; alternatives had a steep learning curve or lacked optimization. However, this is changing. Huawei’s software stack (CANN and MindSpore) has improved and even provides tools to port PyTorch/TensorFlow models to Ascend seamlessly. Baidu’s PaddlePaddle natively supports Kunlun chips. Alibaba’s cloud API hides the hardware specifics from users, meaning they can swap in their chip without developers needing to know. AMD’s ROCm is maturing and is an open-source platform, which China can build on without restriction. All these mean the barriers to using domestic chips are lower than before. Ant Group’s success in matching Nvidia H800 results using Chinese chips confirms that the software and algorithms were tuned well enough to compensate for any hardware differences.
In summary, Ant Group utilized Chinese chips for their affordability and strategic value, while leveraging MoE to mitigate any performance gap. By combining chips from Alibaba (like Hanguang) and Huawei (Ascend), along with some use of Nvidia and AMD hardware, Ant built a heterogeneous computing platform. This mosaic of hardware allowed them to avoid bottlenecks or over-reliance on one supplier. If one device type was slower, MoE could partition the model to assign it appropriate portions of work; if memory was a limitation on one chip, another chip could handle that part. The result was a balanced system where cheaper domestic chips shouldered a significant portion of the load, lowering overall cost by 20%.
Reducing Dependency on Nvidia
A Strategic Shift
A major implication of Ant Group’s approach is a reduced dependency on Nvidia and other foreign chipmakers. By proving that high-performance AI models can be trained without exclusive use of Nvidia GPUs, Ant is charting a path for many Chinese tech firms navigating export controls. As TechRepublic noted, Ant’s MoE training method “combines both Chinese and U.S.-made semiconductors, helping reduce computing costs while limiting reliance on major single-chip suppliers like NVIDIA.”. This diversification is crucial in the current climate.
Consider the context: Nvidia currently dominates the AI hardware market – by some estimates, Nvidia GPUs account for 98% of the global AI training market. In China, companies like Baidu, Alibaba, Tencent have been long-time clients of Nvidia, buying thousands of A100/H100 GPUs for their data centers. This one-company dependence poses a risk when geopolitical tensions interfere. U.S. export bans in 2022 and 2023 specifically targeted Nvidia’s AI chips, cutting off China’s access to the state-of-the-art hardware needed for frontier AI development. Although Nvidia responded by offering slightly neutered versions (A800, H800) for China, the U.S. tightened the screws further, and by late 2023 even those were restricted. This left Chinese tech firms in a lurch – either pause certain AI projects, pay an enormous premium for any remaining stock of older GPUs, or pivot to domestic alternatives.
Ant Group’s shift is a clear example of the third option: pivoting to homegrown alternatives and smarter algorithms. Even though Ant hasn’t completely eliminated Nvidia hardware (they reportedly “continue to utilize Nvidia’s hardware for certain tasks”), they are “increasingly relying on alternatives – particularly chips from AMD and Chinese manufacturers – for latest models.”. The goal is explicitly to eliminate reliance on high-end GPUs over time. This is a strategic bet: if Ant can achieve its AI goals with Chinese chips + clever modeling (MoE), then Nvidia’s stranglehold is broken, at least for them. In effect, Nvidia becomes just one of many suppliers, not a gatekeeper.
The inclusion of AMD is also notable. AMD’s GPU accelerators (Instinct MI series) are not subject to the same export bans and can be purchased freely. While AMD’s market share in AI is small compared to Nvidia, Chinese companies see AMD as a useful “second source”. Ant Group using AMD hardware in the mix gives them leverage – Nvidia no longer dictates all terms. If Nvidia’s prices go too high or supply too low, AMD can fill the gap. Moreover, AMD’s open ROCm software could be customized locally, furthering independence. This dynamic – Nvidia vs AMD – is somewhat reminiscent of how big cloud companies in the West negotiate: they pit Intel vs AMD for CPUs to get better deals. Now in AI, Chinese firms can pit Nvidia vs AMD vs local chips for GPUs. It’s an ecosystem diversification strategy. In Jensen Huang’s own words, some Chinese clients “will try to build their own chips to go around us.” Ant’s example shows they are succeeding in that effort, at least to a degree.
Another aspect of reducing dependency is the know-how and talent. Historically, Chinese AI engineers were most familiar with Nvidia GPUs and CUDA. But as teams at Ant, Baidu, Alibaba, Huawei, etc. work more with domestic chips, a base of expertise grows. For instance, Ant’s engineers undoubtedly had to optimize TensorFlow/PyTorch to run on Ascend and perhaps write custom kernels for their MoE model. That knowledge accumulation means next time it will be easier and more efficient. In the long run, that erodes Nvidia’s lock-in advantage of software. Already, tools exist to convert models to run on Ascend or Kunlun with minimal code changes. The more success stories like Ant’s, the more confidence others will have to follow suit, and the more the ecosystem around Chinese chips will flourish.
From a financial perspective, relying less on Nvidia also insulates Chinese firms from Nvidia’s pricing power and supply constraints. In 2023, Nvidia’s H100 demand far outstripped supply, leading to long lead times. Chinese buyers, facing both scarcity and a potential ban, were sometimes paying markups or rushing orders. By developing a route to quality AI outcomes without only Nvidia, companies like Ant can negotiate better or be more patient. It’s a hedge against geopolitics: if a new ban comes, Ant’s core capabilities won’t be crippled; they have an in-house solution. This is echoed by analysts who say China’s market will evolve such that “Nvidia will be one part... and domestic chips will be another. Global computing power will become two parallel lines.”.
All of this is not to say Nvidia is being completely replaced. It still features in many training pipelines for now. But Ant’s achievement undermines the notion that state-of-the-art AI requires state-of-the-art Nvidia silicon. In fact, Ant effectively disproved Jensen Huang’s assertion that cutting costs means compromising progress – they cut cost and matched H800 performance. It’s a powerful message: there is an alternative path.
Baidu and Alibaba Cloud: Similar Cost-Cutting Strategies
Ant Group is not alone in this journey. Other Chinese tech giants, notably Baidu and Alibaba (Alibaba Cloud), are also pursuing strategies to cut AI costs through a combination of custom chips, efficient model architectures, and aggressive pricing. Let’s look at each:
Baidu’s Approach: Baidu has been investing in AI hardware and model efficiency for years, driven by its needs in search, cloud, and autonomous driving. They developed the Kunlun AI chips (mentioned above) to reduce dependency on Nvidia and power their AI platform. Baidu’s AI cloud platform (Baidu Brain) is a full-stack that integrates Kunlun chips, the PaddlePaddle deep learning framework, and the ERNIE large models. By vertically integrating, Baidu can optimize at all levels to save cost. For instance, PaddlePaddle has routines to make the most of Kunlun’s architecture, achieving similar throughput to GPUs for some tasks. Baidu has reported that Kunlun II inference throughput is 3× faster than conventional GPU/FPGA on certain NLP models, demonstrating cost or speed gains in real deployment.
Moreover, Baidu has actively begun using other domestic chips. An exclusive Reuters report in late 2023 revealed Baidu placed a large order for Huawei’s Ascend 910B chips – 1,600 chips for about 200 servers. This was a proactive move anticipating U.S. export rule tightening. The deal, though small relative to past Nvidia orders, is symbolically significant: Baidu is willing to put Huawei’s silicon into its data centers, something not done at scale before. By end of 2023, Huawei had delivered most of those chips to Baidu, and the two companies announced deeper collaboration to ensure Baidu’s AI (like the ERNIE model) runs well on Ascend hardware. This mirrors Ant’s move – diversifying hardware and optimizing software for it. Baidu still primarily used Nvidia A100s to train its earlier ERNIE versions, but as A100/H100 became restricted, Baidu is shifting new training to alternatives, even if performance is a bit lower, because they value self-reliance and cost consistency.
On the model side, Baidu has also been innovating to reduce inference costs. After launching its ERNIE Bot (a ChatGPT-like model), Baidu introduced Ernie Fast and Ernie Lite – distilled or smaller versions offered for free to business users. In May 2024, Baidu made these light models free of charge, effectively cutting the price per token to zero for users. This radical price drop was only possible because Baidu found ways to run these models very cheaply internally. Baidu’s CEO mentioned that Ernie 4.0 (or Ernie 4.5) could match GPT-4 level performance at only 1% of the cost in some benchmarks (a claim circulated in media) – suggesting heavy use of model compression and retrieval techniques to avoid brute-force size. And in early 2025, Baidu unveiled ERNIE X1, a new “reasoning AI” model, claiming it matches DeepSeek’s performance at half the price. Since DeepSeek’s hallmark is low cost, Baidu essentially said we can do it even cheaper. These announcements indicate Baidu is fully engaged in the AI cost war, employing both hardware (Kunlun, Ascend) and software (MoE, knowledge distillation, optimized reasoning modules) to slash costs. Baidu’s president reportedly said Ernie 3.5 was trained on a mix of 2,000 Nvidia GPUs and 400 Kunlun chips, showing a gradual transition to their own chips.
In summary, Baidu’s strategy parallels Ant’s: invest in domestic chips (Kunlun, Ascend), optimize models for efficiency (distill smaller versions, perhaps MoE in future), and even be willing to sacrifice some margin by offering AI services cheap or free to gain market share – a move only feasible because their internal costs are dropping.
Alibaba Cloud’s Approach: Alibaba’s cloud division (Aliyun) is another key player. Alibaba has the dual advantage of being both a cloud provider and having in-house chip design (via Pingtouge) and a strong research team for models (DAMO Academy). Like Baidu, Alibaba has rolled out measures to aggressively cut AI costs:
- Custom Chips in Cloud: Alibaba uses its Hanguang 800 inference chip within its cloud services. For example, after Hanguang 800’s launch, Alibaba offered an AI inference service that was 100% more efficient (2×) than GPU-based VM instances. This means customers (and internal teams) could run inference workloads at half the cost. By not having to use expensive Nvidia T4/A10 GPUs for every inference job, Alibaba Cloud could undercut competitors on price for AI inference. Although Hanguang 800 is not (yet) used for training large models, it offloads a huge portion of work (serving the models to users) from costly GPU servers.
- MoE-based Large Models: As noted, Alibaba’s research arm developed the Tongyi Qwen-2.5 series, large language models that incorporate MoE for efficiency. The Qwen-2.5 Max model, introduced in late 2024, reportedly runs with 70% fewer FLOPs than dense models. This allowed Alibaba Cloud to dramatically lower the cost of usage. In May 2024, Alibaba announced price cuts up to 97% on its LLM API services. To put numbers on that: their Qwen-Long model’s price dropped from ¥0.02 to ¥0.0005 per 1,000 tokens – i.e., from 2¢ to 0.05¢ in yuan, or roughly $0.07 per million tokens. This is an astonishing reduction and clearly not a subsidized loss-leader; it reflects real underlying cost improvements. For comparison, OpenAI’s GPT-4 is estimated around $7.50 per million tokens (for certain usage), and even GPT-3.5 is a few dollars per million. Alibaba is now offering generative AI API calls for mere cents per million, undercutting OpenAI by orders of magnitude. This was only possible due to the combination of MoE efficiency and perhaps running the model on cheaper hardware (Aliyun can schedule these models on a mix of Nvidia, AMD, and Alibaba’s own chips depending on load). The result: Alibaba triggered a price war in China’s cloud – Baidu quickly responded by making some models free, and ByteDance priced its model 99% lower than peers. For customers, this is great; for Alibaba, they believe volume and cloud retention will make up for thin margins. But crucially, they could not have done this if their cost to serve each request wasn’t equally low.
- Reducing Nvidia Dependence: Alibaba, like Baidu, has also been exploring non-Nvidia hardware for training. There were reports of Alibaba testing Biren Technology’s GPUs (a Chinese startup) before sanctions hit Biren. Alibaba Cloud also offers instances with AMD MI200 GPUs to customers, indicating their team has experience with ROCm and non-CUDA environments. Alibaba’s chip division T-Head is reportedly working on a training accelerator as well. And Alibaba has a history of using FPGAs and other custom accelerators in its cloud (for example, deploying FPGAs for search ranking algorithms to avoid only CPUs/GPUs). This diversified approach means Alibaba Cloud can gradually swap in more domestic tech as it becomes viable, much like Ant did internally.
In essence, Alibaba Cloud’s strategy is to own the whole stack: use custom chips for inference, use advanced model architectures (like MoE and knowledge-enhanced models) to cut compute needs, and pass those savings on to customers in the form of drastically lower prices. This makes it hard for competitors who rely purely on expensive foreign GPUs to keep up, and it drives higher adoption of Alibaba’s services – a virtuous cycle that gives Alibaba more scale to amortize chip R&D and software investment.
How do these compare to Ant Group? Ant, not being a public cloud provider, isn’t slashing API prices for external users, but internally it mirrors these moves: adopt domestic chips (like Baidu), adopt MoE models (like Alibaba), and aim for cost leadership in AI operations. One could say Ant Group is implementing a mini-Alibaba/Aliyun strategy within its own organization. Given Ant’s close ties to Alibaba (Ant was an affiliate of Alibaba Group), it’s not surprising they collaborated on chips and possibly on the MoE model front as well.
What’s striking is a collective trend: the largest AI players in China are all converging on the idea that efficiency and cost reduction are the new battleground, not just model quality. Models from Baidu, Alibaba, DeepSeek and others are now competing on who can deliver the same performance for lower cost. This contrasts with a past era where everyone raced just for higher accuracy or bigger parameter counts.
The Chinese firms are, in effect, pioneering a new playbook for AI in a resource-constrained environment: innovate to do more with less. Ant Group’s 20% cost cut is one chapter in this playbook, and Baidu’s free models and Alibaba’s 97% price cut are other chapters. Together, they indicate a paradigm shift in AI development priorities.
Nvidia vs Domestic Solutions
Cost, Performance and Ecosystem
It’s useful to directly compare the Nvidia-centric approach vs the new domestic/MoE approach in terms of cost, performance, and ecosystem considerations:
- Cost: Nvidia’s top GPUs (like the A100, H100) are extremely expensive – not just to buy, but also to operate (power, cooling, infrastructure). They are often worth the cost for cutting-edge research because they deliver results faster. However, when cost is a constraint, their premium becomes a problem. The domestic approach – using cheaper local chips plus model efficiency – can yield dramatic cost savings at some performance penalty. Ant Group’s case: 20% lower cost for comparable training output. Alibaba’s case: 70% less compute for same model quality, which presumably translates to a similar magnitude of cost saving. And DeepSeek’s example: 90–95% cost reduction for training/inference combined, compared to Western counterparts. These are game-changing numbers. Nvidia’s solution to heavy AI demand is “buy more H100s” – which at ~$30k each, pushes costs higher. The Chinese solution is “use ten $3k cards with smart algorithms instead of one $30k card” – which one makes CFOs happier is clear. Figure 2 illustrates how sharply Chinese AI providers have driven down the price of AI service relative to the baseline:
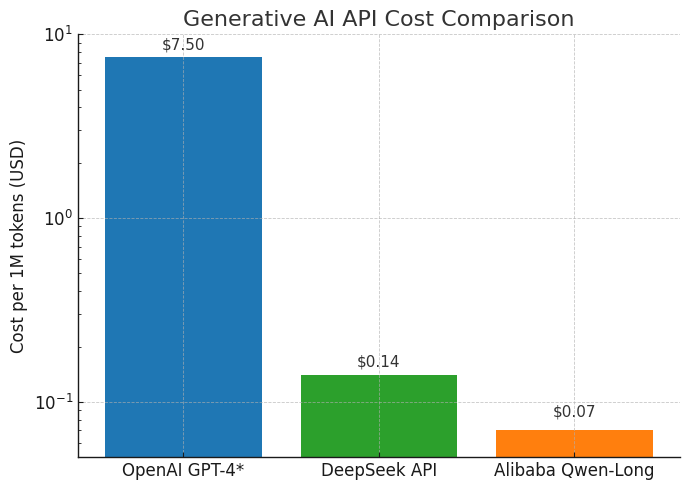
Figure 2: Generative AI API cost comparison (per 1 million tokens). Chinese firms leveraging MoE and domestic chips offer AI model usage at a tiny fraction of traditional costs. Alibaba Cloud’s Tongyi Qwen-Long model costs about $0.07 per million tokens after a 97% price cut. Startup DeepSeek offers around $0.14 per million tokens. These are two orders of magnitude cheaper than some OpenAI GPT-4 costs (which can be around $7.50 per million tokens). Such low pricing is only viable due to equally significant reductions in underlying compute cost.
In enterprise terms, cost-performance (bang for buck) is increasingly favoring the new approaches. Nvidia still gives the absolute best performance – e.g., if you need to train a model in 1 day instead of 2 days, H100 might be the only option. But if you can wait a bit longer or use more units of a less powerful chip, you can save significant money. Many business applications care more about cost-efficiency than shaving off training time at any expense. For inference, if you can handle 1,000 queries for $1 on Nvidia or the same 1,000 queries for $0.10 on a combination of Ascend chips, the latter is hugely attractive for a deployed service at scale.
- Performance: In terms of raw performance, Nvidia is still ahead. The H100 GPU introduces new features (like FP8 precision, transformer engines) that give it superior speed on large language models. Chinese chips are catching up but are a generation or two behind. For example, Ascend 910’s ~320 FP16 TFLOPS equals Nvidia’s 2020 A100; Nvidia’s 2022 H100 can surpass 1,000 TFLOPS in certain modes (with sparsity or FP8). Also, Nvidia’s architectures have very fast interconnects (NVLink, NVSwitch) that allow many GPUs to work in parallel efficiently – something critical for training huge models. Chinese alternatives often rely on standard PCIe or slower interconnects, making large-scale synchronization less efficient. This is why Nvidia “maintains its indisputable lead” in heavy AI training tasks for now, as DeepSeek’s analysis pointed out. They mentioned that long-term training reliability was a weakness of Chinese processors, partly due to the less mature ecosystem and possibly hardware stability under extreme load. So, in scenarios that demand utmost performance (e.g., training a new 100B model under tight deadline, or fine-tuning multiple models daily), Nvidia still has an edge.
However, the gaps are narrowing for many practical tasks. As noted, Huawei’s latest chips can reach ~60% of H100 performance in inference. For many companies, 60% of top-tier performance at perhaps <50% cost is a worthy trade-off. Also, MoE architectures complicate the notion of performance: an MoE model might require less performance to achieve the same accuracy, effectively making a slower chip behave like a faster one in terms of end results. Ant’s experiment showed a lower-spec hardware setup produced the same model quality as a high-spec setup, just more efficiently. Thus, while a single Ascend chip is slower than a single H100, if you can reach the objective with fewer total FLOPs thanks to MoE, the system-level performance is a match.
In benchmarks, we are seeing Chinese models built on these strategies beating Western models. For instance, DeepSeek’s model reportedly outperformed OpenAI’s GPT-4 on certain benchmarks, despite presumably running on far less advanced hardware. That implies performance where it counts (accuracy, user experience) was achieved without matching hardware spec-for-spec.
- Ecosystem and Support: This is where Nvidia still has a big moat. The CUDA software platform, libraries (cuDNN, TensorRT), and developer community around Nvidia are unparalleled. Decades of optimization mean most AI code “just works” out-of-the-box on Nvidia, and engineers are very familiar with it. By contrast, using a new Chinese chip might require learning a new SDK, dealing with immature tooling, or encountering bugs that have long been solved in CUDA. As DeepSeek’s team noted, sustained training workloads needed further improvements in Huawei’s hardware/software stack– meaning issues like handling very large batch sizes, scaling to multi-chip training, etc., were areas where Nvidia’s polished software shines and Huawei’s might struggle initially.
That said, the ecosystem for alternatives is improving rapidly. Open-source AI frameworks are making it easier to plug in new backends. PyTorch, for instance, has a backend for AMD (ROCm) and one for Huawei Ascend (using plugin libraries). One can train a model in PyTorch and with minimal code switch to target Ascend – though some performance tuning is needed to get close to Nvidia speeds. Community support is growing too: Huawei has hosted code on GitHub, and Chinese forums are active with tips for using domestic hardware. The Chinese government and companies are also investing in talent development for AI chips, which will increase the pool of engineers comfortable with them.
Nvidia also has a robust software ecosystem (NVIDIA AI) including pretrained models, SDKs for specific domains (e.g., Isaac for robotics, Clara for healthcare) that are not easily replaced. Chinese companies are countering this by open-sourcing models (e.g., Baidu released some Ernie versions, Alibaba open-sourced parts of Qwen) and developing their own libraries. Over time, a parallel ecosystem is emerging inside China: for example, MindSpore (Huawei’s deep learning framework) and PaddlePaddle (Baidu’s) are both official “national AI platforms” and have growing user bases. If developers use those, they might directly develop on Chinese hardware skipping Nvidia-centric tools altogether.
In summary, Nvidia still enjoys a mature, plug-and-play ecosystem with maximum performance, whereas domestic solutions offer a more cost-effective, controllable ecosystem that’s rapidly improving. We’re likely to see both co-exist: Nvidia for cutting-edge requirements and where cost is secondary, domestic chips for mainstream deployment where cost and independence matter more.
Conclusion
Ant Group’s effort to trim AI costs by 20% using domestic semiconductors and Mixture-of-Experts models is a bellwether for the AI industry. It shows that bigger isn’t always better – smarter is better. By cleverly splitting a colossal AI model into “experts” and running it on a mosaic of Chinese-made chips, Ant achieved results on par with top-tier Nvidia systems at a fraction of the expense. In doing so, Ant Group not only saved money and reduced its dependence on foreign technology, but also demonstrated a viable path forward for others grappling with the high cost of AI.
We learned about the inner workings of MoE models and how they allow one to scale AI to hundreds of billions of parameters without a proportional scale in computation – a timely solution as we reach the limits of what brute-force methods can deliver cost-effectively. We saw that China’s domestic semiconductor capabilities – from Huawei’s Ascend chips to Alibaba’s Hanguang and Baidu’s Kunlun – have matured to the point of taking on serious AI workloads, heralding a new era of homegrown innovation. We compared these approaches with Nvidia’s, recognizing that while Nvidia still leads in raw power and ecosystem maturity, the ground is quickly shifting under the feet of the AI hardware status quo. Cost-performance and accessibility are becoming as important as absolute performance.
Both Baidu and Alibaba Cloud are parallel protagonists in this story, likewise leveraging custom chips and model optimizations to slash AI costs and even igniting a price war in AI services. The convergence of strategies among China’s tech giants signals a broader movement – one focused on pragmatic and sustainable AI development. In a sense, the narrative of AI in China is evolving: from chasing state-of-the-art at any cost, to achieving state-of-the-art with an eye on cost. This could make AI solutions more pervasive across industries, as the barrier of high compute cost is lowered.
For China’s tech ecosystem, Ant Group’s success strengthens the resolve to pursue semiconductor self-sufficiency and novel AI techniques. For the global AI community, it offers an alternative model to consider: one that could influence best practices worldwide, especially as companies everywhere grapple with the compute demands of AI. There will always be a place for the biggest and fastest chips, but Ant Group has shown that there is also immense value in innovation aimed at efficiency and resilience.
In conclusion, Ant Group’s 20% cost reduction is more than a financial statistic – it’s a statement. It declares that the future of AI need not be chained to the most expensive hardware or singular approaches. With creativity in model design and a willingness to break from traditional reliance on a single supplier, significant gains can be made. As AI continues to transform industries and societies, such advances in cost-efficiency and hardware diversity will play a crucial role in determining who can harness AI’s power – and at what price. Ant Group has given us a glimpse of an AI landscape that is more cost-conscious, more multi-polar in hardware, and no less capable. That is a breakthrough worth noting, and one likely to reverberate across the AI world in the coming years.
References
- TechNode – “Ant Group cuts AI costs by 20% using Chinese chips”technode.comtechnode.com
- Tom’s Hardware – “Ant Group… reduces AI costs 20% with Chinese chips”tomshardware.comtomshardware.com
- TechRepublic – “Ant Group Slashes AI Costs by 20% With Chinese-Made Chips”techrepublic.comtechrepublic.com
- Ant Group Research (Ling et al., 2025) – “Every FLOP Counts: 300B MoE LLM without Premium GPUs” (arXiv)ar5iv.orgar5iv.org
- IBM – “What is mixture of experts?” (2024 explainer)ibm.comibm.com
- Asia News Network/China Daily – “DeepSeek to help Chinese AI chip firms challenge Nvidia”asianews.networkasianews.network
- Tom’s Hardware – “DeepSeek research: Huawei’s Ascend 910C at 60% of Nvidia H100”tomshardware.comtomshardware.com
- Reuters – “Baidu placed AI chip order from Huawei in shift away from Nvidia”reuters.comreuters.com
- Reuters – “Chinese tech giants slash prices of LLMs… price war in cloud”reuters.comreuters.com
- Twimbit – “AI’s Next Battleground: OpenAI, Alibaba, and DeepSeek”twimbit.comtwimbit.com
- Medium (Synced) – “Alibaba’s Hanguang 800 – 80K images/s, 15× NVIDIA T4”medium.com
- Tom’s Hardware – “Baidu Kunlun II AI Chip: rival for Nvidia A100”tomshardware.comtomshardware.com
- CSET Georgetown – “Huawei’s AI Chip tests U.S. Export Controls”cset.georgetown.edu(Ascend 910 ~320 TFLOPS ~ A100)
- Wall Street Journal – “Baidu launches reasoning AI model, half the price of DeepSeek”wsj.com(performance vs price claim)
- Additional references from CNBC, SCMP, etc., as embedded abovecnbc.comtechnode.com.